
(圖為中研院國際會議廳 /來源:資料科學愛好者年會)
撰稿:陳宣毅、謝宜珊
資料科學在生活中的運用不勝枚舉,從Amazon的推薦系統,到Facebook自動選擇讓我們看到哪些動態,背後都有龐大的數據奔流,以及一群資料科學家分析與研究。今年1月,台灣資料科學愛好者學會舉辦「資料科學的第一堂課」,講者陳昇瑋是中研院資料科學研究所研究員,也是年會總召。本文整理年會重點,文末附上陳教授報告的投影片以及與會者們的共編筆記。
 (陳昇瑋教授,來源:資料科學愛好者年會)
(陳昇瑋教授,來源:資料科學愛好者年會)
資料科學有如淘金
科學是用系統性的方法來建立和組織知識,並可以用來測量、反覆驗證、解釋和預測;而資料科學就是用科學方法,來幫助我們從資料中分析、取得知識的科學。
 (淘金圖,來源:Brian Harrington Spier)
(淘金圖,來源:Brian Harrington Spier)
資料科學分析的過程非常像是淘金,而淘金有多難?要從土地上挖出一千公斤的土,然後慢慢淘選分析,如果在這一千公斤的土中含有五公斤的黃金,就代表這塊土地具有淘金的價值。過去我們分析資料時,只用Excel來分析,就像是徒手淘金;現在我們有更方便、更好操作的工具來幫助我們分析資料,而這些工具未必是軟體工具,更多的是新的理論模型,像是數學、統計學以及相關延伸的理論與技術。透過這些新工具,讓我們在分析資料時,能夠更快上手,並且淘取我們所需要的知識。
大數據(Big Data)不是只有海量就好!
陳昇瑋教授2016年3月8日在經濟日報上發表「別讓大數據變玄學」一文中提到:「大數據指的是因應過去技術平台無法處理大量、快速產生、無結構性或需要即時回應的資料所衍生的新一代技術的集合。並不是數據量要大,要海量,才能有價值。」近年來,政府與民間都大力推動大數據的相關研究,到底什麼是大數據呢?2001年資料分析師 Doug Laney提出大數據料擁有三種特性(3 Vs),如果所處理的資料擁有這三種特性之一,就屬於大數據。
第一是大量(Volume):伴隨電子商務的蓬勃、資料傳輸管道成本的降低,現今的資訊技術可以處理的資料愈來愈大量。如果處理的資料量規模達到數兆位元組(terabytes, TB)的資料量規模,即稱為大量。
第二是持續快速產生(Velocity):指每一秒鐘會即時地產生數十萬筆的紀錄檔,形成所謂的串流資料(Streams Data),這種資料的特性是寫入的速度非常快速,會源源不絕不斷地寫入資料庫中。例如在Twitter或Facebook上每秒的發文、每秒在搜尋引擎中搜尋產生的紀錄檔。
第三是多樣性(Variety):有兩種層面的意思,一種為資料領域的多樣性,當處理資料時,將完全不同領域的資料一起合併來做分析。例如:麵包店除了看原本麵包相關的報表,現在也可以把其他領域的資料共同納入考量,例如氣象、交通資料等等放進來一起分析,將異質性資料的結合做成本分析。另一種是資料格式上的多樣性,可以大致區分為結構性資料與非結構性資料,前者是能夠被量化、容易組織的資料,像是書目紀錄或稽核項,而後者則像是Facebook的發文、照片、通話紀錄或是影像……等較難處理。
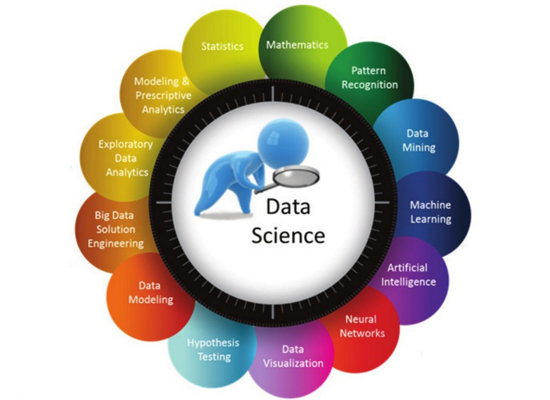 (資料科學子領域圖,來源:陳昇瑋)
(資料科學子領域圖,來源:陳昇瑋)
Big Data的成名與迷思
大數據近來熱門的原因包含:
一、容易收集跟處理資料。隨著儲存資料的硬體設備愈加便宜、可以儲存的容量愈來愈大,再加上各種用於分析、處理資料的軟體相對普及,故透過資料分析,將分析結果應用於開發相關專案的機會也愈來愈多。
二、拜網路便利所賜,容易有大量的網路使用者出現。
三、政府推動開放資料,讓資料集(dataset)的取用更容易。
四、各種感測裝置(sensor)的普及,例如:錄音工具、手機感測軟體、相機錄影設備,讓大眾暴露在容易被感測、記錄相關資料的環境中。
但是,講者認為臺灣的公司有八成不需要使用到大數據分析,因為大數據的分析要視使用需求而定,而臺灣多數公司所擁有的資料量,其實未達到大數據分析的標準,只要應用傳統的資料分析技術就可以達到同樣的分析效果。例如:圖書館對使用者借閱紀錄的分析,如果資料量未達到兆位元組(TB),利用Excel函數的資料分析方法就可以達到同樣的效果。
資料科學+社會學=計算社會學
應用資料科學的另一項熱門領域是計算社會學,計算社會學是來自資料科學與社會學的結合,研究資料中人與人的互動關係,從中建立模型與預測。常見的研究方法有三種:第一種為大尺度觀測(Macroscope),例如:觀察人使用的語言的特性,或是利用Facebook使用者發文的常用詞彙來分出不同性別、年齡、興趣、個性的族群。
第二種是將網路作為實驗空間,例如:Facebook曾施行操作情緒的實驗,隱藏使用者在動態中的正面或負面情緒的發文,發現人們很容易受所看到的發文而影響心情。不過,這個實驗也引發研究倫理方面的爭議,Facebook在事後才在使用者條款上加上可能將使用者的資料作為研究用途。另外,Facebook也增加了一些功能來改變社會,例如:Facebook新增「I voted」之功能,提醒使用者其朋友中,有多少人已經去投票,間接促使選民改變心意,出門投票。又例如今年過年期間發生的南台大地震,在地震後Facebook執行長馬克•祖克柏(Mark Zuckerberg)隨即在Facebook發文發布新功能「Facebook平安通報站」,讓使用者在線上即時回報自己是否安全,避免讓親朋好友擔心自身安危。
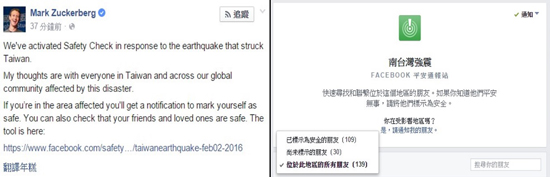 (左:馬克•祖克柏的發文;右:Facebook平安通報站,左圖來源:馬克•祖克柏;右圖來源:Facebook)
(左:馬克•祖克柏的發文;右:Facebook平安通報站,左圖來源:馬克•祖克柏;右圖來源:Facebook)
第三種是透過大尺度觀測後,將觀測到的結果依經驗建立模型來預測人們的行為。例如:透過分析Facebook按粉絲團讚的行為,來建立預測使用者是男性、女性,或是已婚、未婚的模型;又如使用者若點選類似「卡提諾正妹抱報」這類充滿許多正妹貼圖的粉絲團達一定比例,就可以透過模型預測使用者是男性;若點選許多「嬰兒與母親 懷孕生產情報站」這類粉絲團,就能預測是已婚女性。
利用資料科學設計熱銷商品
資料科學也可以對你的工作有所幫助!想像一個情境:你現在正在一間線上遊戲公司工作,公司的主要收益來自玩家購買角色服裝,而你擔當與設計師溝通職責,試問,你要如何分析「服裝」,才能告訴設計師哪些款式的服裝會大賣?
面對無法量化的非結構性資料,第一步,你必須先將它轉化成結構性資料,最好的辦法就是請教該領域的專家,請他分析並列出有關該產品的屬性(attribute)。回到虛擬服裝的例子,你可能要請益cosplay的專家,請他列出服裝的「風格標籤」,例如:甜美、華麗、侍者、女傭……。收集而來的標籤就是服裝的「語意屬性」(sematic attribute)。擁有完整、合適的屬性能為後續的資料分析打好基礎,故資料科學家非常重視與目標領域的專家合作,因為列出正確的特點才能有精準的預測。
 (將服裝分為多個屬性以分析玩家嗜好;來源:FluffyLtd)
(將服裝分為多個屬性以分析玩家嗜好;來源:FluffyLtd)
條列出服裝的屬性後,就可以從眾多玩家的背景資料,包括:性別、年齡、上機時間、週期、偏好服裝等,分析出影響虛擬服裝銷售量的因素有哪些,也可以找出各年齡層愛好的服裝屬性為何,最後配合個人化推薦系統,增加產品曝光率以達到有效銷售的目標。
總而言之,非結構性的資訊物件,如上述舉例的遊戲角色衣服,若能列出他們的屬性和特色,其實後續的大數據分析就已經成功了一半。找某項產品的特徵原本就需要對該領域有一定程度的理解,就像麵包師傅一定比一般人更了解麵包,可能光是麵糰的氣味就可以區分出好幾種屬性,所以找專家是最直接的方式。
資料科學協助作公益
 (蘋果日報每日報導的捐款進度報告,來源:蘋果日報慈善基金會)
(蘋果日報每日報導的捐款進度報告,來源:蘋果日報慈善基金會)
在蘋果日報慈善基金會的網頁上你看到三個報導標題:
「男半癱腦損 看影片認兒」
「夫癱兒逝 嬤送報養2孫」
「稚兒畫卡片 為癌父加油」
若要捐款,你最先想捐給哪個受訪者?
大部分的人都會被第二個報導的標題吸引住,認為這個案例最可憐,捐款應該優先給他,是什麼原因讓我們在眾多的弱勢關懷報導中,選擇某些案例捐款呢?蘋果日報基金會必須掌握這把關鍵鑰匙,好讓每個案件都能達標。陳昇瑋教授以資料科學分析受訪者與捐款多寡的關係,他找了捐款數目最高與最低各25%的案例來分析,因為受訪者是人,屬於非結構性資料,須轉化成結構化的屬性(如:受訪者的性別、年齡、工作、傷殘程度、家庭成員、疾病類型、精神狀態……),從這些變數中找出影響捐款多寡的決定性因素,此外,報導的方式也納入影響因素,包括:採訪記者、報導上的圖片與標題、登刊時間。
做完綜合分析後,他發現捐款意願與時間點密切相關:五月納稅季節最少人捐款,過年時年終尾牙荷包滿,捐款意願也最高;星期三的捐款比例是一個星期中最多的,而星期五最少。此外,他發現越胖的受訪者得到捐款的機率越高,嗷嗷待哺的孫子個數越多,也會得到較多捐款。得出這些有趣的結果後,資料科學家還有一件重要工作──解釋現象發生的原因。陳昇瑋教授藉此例分享,他認為正因為總有無法預料的變數影響結果,資料科學家應避免預設立場,否則可能會遺漏隱藏的重要變數。
小結
資料科學聽起來雖然像是資工領域的範疇,但其實圖書資訊學的課程,舉凡大學部的圖書館統計學、資訊組織、資訊心理學;大學部高年級與碩士班選修的資訊視覺化、社會網絡分析、資料庫管理系統;以及研究所的量化研究與統計分析、資訊蒐集與決策等諸多課程,都能培養學生系統性思考、分析並詮釋數據。如果你開始對資料科學產生興趣,不妨去逛逛台灣資料科學愛好者年會,接下來系網團隊還會帶給大家更多相關報導喔!
參考資料:
陳昇瑋(2016)。資料科學的第一堂課:心法、案例分析與團隊建立。取自http://www.iis.sinica.edu.tw/~swc/talk/data_science_overview.html
資料科學面面觀共編筆記。網址:https://hackpad.com/F5mpOfHzepS;上網日期:2016年3月7日。
Laney D (2001) 3-d data management: controlling data volume, velocity and variety. META Group Research Note, 6 February.
文章分類: 新聞報導